Hey all! I wanted to share two leaflets I just posted on the topic.
Neither of these are attempts to solve the problem. They’re more to help us scope and shape the situation, and generate some thoughts on the solutions.
Hey all! I wanted to share two leaflets I just posted on the topic.
Neither of these are attempts to solve the problem. They’re more to help us scope and shape the situation, and generate some thoughts on the solutions.
Love to see this coming from you !! Reading now ![]()
![]()
Ha! I started a topic for the first one - have just merged it in as a comment of key quotes.
Thanks @pfrazee.com for the write up!
This sets up our initial requirements for private data in AT: we want to handle personal-private and shared-private data; We do not want to increase the operational or resource costs of the PDS; we don’t want to sacrifice generality; and we need applications to sync the private data.
On Personal Private:
The “personal-private” storage is unshared private data. It’s useful for state like preferences, bookmarks, and drafts. It could also store documents, notes, pictures, TODOs, and any other kind of data a user might want to keep in their personal server.
On Shared Private:
The “shared-private” storage is for data which is multi-user but non-public. Some common use-cases include posts, user lists, videos, documents, DMs, and basically any other kind of artefact or experience in social or productivity software.
Everyone should read the whole thing!
A comment I have on first read is that I would prefer not seeing DMs being called out as a use case - private threads or forums might be better labels.
(Can we explain the difference? Do these things fit into the same jobs-to-be-done space as DMs? Maybe!)
One could implement “less secure” or “less private” DMs with a private data scheme but I personally think those efforts are better spent on E2EE messaging.
Love to see this coming from you !! Reading now ![]()
![]()
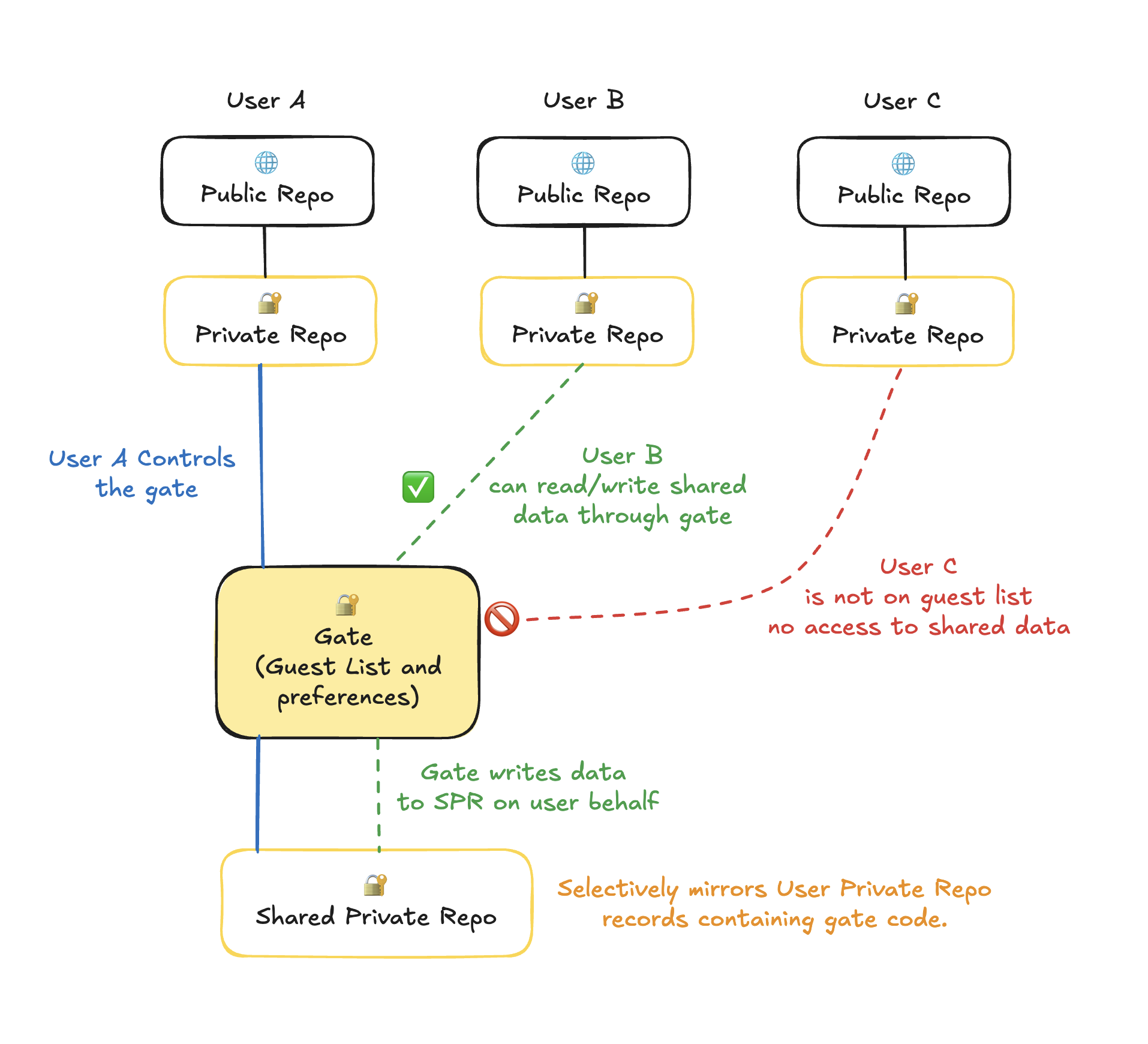
Okay, so this sparked some ideas for me which are at this point pretty surface level. I’ve sketched out a chart for a shared private data flow that assumes non shared private repos exist and is somewhere between your hosted arena scheme and the synced arena scheme while still allowing users to retain ownership of their data.
I am already seeing flaws with my idea but wanted to share anyway in case it inspires anything else and so that it can at least be further discussed (or torn apart lmao.)
Thanks for these! I’ve been thinking a lot about the ending of the three schemes leaflet:
It’s possible that all three might be needed, or that a secret fourth (or fifth!) might be out there.
I wonder if it’s possible for us to avoid needing to make tradeoffs between scalability, metadata privacy, and not needing a trusted authority involved that breaks assumptions about what decentralized privacy looks like- not to mention the criteria from more complicated cases like supporting E2EE- but it seems like we’re inevitably forced to choose to compromise on something. If I had to choose in this tradeoff, there are multiple types of services I’d want to build on-protocol that would benefit from different mixes of the options, which makes having all the choices possible sound very tempting. But of course, that bumps up against one of the criteria that’s a bit different from the rest…
How accessible is the developer experience and API surface?
I assume this can be simplified to requiring developers to learn one more thing, with that thing being dependent on the implementation of private data that fits their needs, but I suppose that it’s also as complicated as understanding what the benefits and drawbacks to each are. But I’m also thinking about the toll on third party protocol infra devs; for someone who implements a PDS, or a private relay (whatever that could end up meaning), multiple solutions to private data is not only multiple features to implement, but multiple points for the systems backing privacy to fail in the process.
Regardless, maybe it’s something we should be discussing as the best approach to being able to address the needs of all the different use cases in this community. With the expectation in mind that we may need multiple definitions of “private data” in place, we might be able to reach a minimal set of different approaches that cover most of the mixes of specific requirements, be they a variant of the three schemes here or some combo we haven’t considered yet.
This more or less aligns nicely with the direction i was experimenting with.
I am implementing ( testing) a setup where there is a MST (arena) for each unique (cid) permission set ( granted oauth scopes ), all records ( blocks) are part of the private data MST (arena) and based on the cid of a permission set also added (routed) to other MST’s ( arenas ).
The mutations ( commits) in the different MST’s are routed to clients ( apps / recipients ) subscribed to the /xrpc/com.atproto.sync.subscribeRepos endpoint, clientid ( = granted permission set ) and sub ( repo ) in the token decide which MST is providing the events.
In this setup public data is just one of the MST’s ( arena’s )
I described how the E2EE design in Peergos relates to these categories: @ianopolous.bsky.social on Bluesky
Thanks Paul! This was incredibly helpful! And I think the following point kind of illustrates one of the first major decisions / possible places needed to compromise:
Are their notable absences in the supported use-cases, such as private accounts
My immediate thought here was the social media use-case of moving your account to private/back to public – and then how that plays against some of the discussion about how private storage might be different from public storage.
If they’re separate, with different trees, then an operation like “taking your account private” could be very performance intense. The same would go for if the scope was part of the data itself - large updates could be very very bad.
I see a very heavy user expectation that you can seamlessly move data between public/private-personal/private-shared. This is a very common pattern on both social media and cloud document editing. And I think it has the potential to break the “don’t hurt the PDS” piece here if not handled carefully.
Other use cases: Draft posts/articles/etc etc. (private-personal → public or private-shared), Unintentionally Viral Content (or content that is currently unsafe because it’s targeted by bad actors) where you want to keep what you have, but cutoff people’s ability to see the content, temporarily or permanently (public → private).
Now, if it’s something like a layer over the data with a flag within the PDS rather than a different store or requiring a data update, a lot of this is a non-issue.
But, this would end up having to be in the PDS at some level, in a non-intrusive, backwards compatible, way. The PDS might just have bit flags or something super small and quick to say “nope, sorry, gotta ask the right way” (307/308?) and potentially delegate the authority of access to some other trusted service.
I keep leaning towards this “secret 3rd service” option - and a large part of that are these:
We do not want to increase the operational or resource costs of the PDS
and
Are the shared-private systems easy to understand and build with?
I think if you try to make this work in the existing architecture, either one or both of these will be violated or you’re going to be putting it somewhere like the app view where it doesn’t really belong, and breaking:
does it feel like an intuitive extension to AT’s existing primitives
I think its possible to mitigate but not eliminate cost increases to the PDS and still make the developer experience friendly enough. Especially if you can somehow offload a lot of the extra work to a middle tier. I think some of the design’s we’ve talked about essentially have authenticated relays (or relays with authenticated channels) and/or a proxy PDS that would fit for something like this. Minimal PDS overhead, can likely be done with tooling to make it relatively simple, and also would seem rather intuitive as an extension to ATs existing systems.
I hear this:
…but I very much think this is an App-specific problem. That is, at Bluesky AppView scale, and being able to go back and forth like this for the microblog use case, it’s all very performance sensitive as you’ve stated.
It also seems like expectations inherited for the microblog / twitter use case.
I think cloud document editing is much smaller in scale, a total valid use case for flipping between these modes, and way easier to handle. Usually 10s of people not 100s to 1000s.
Might there be some expectation that “app use cases” (like doc editing) can be fit into one bucket, and “social” use cases another?
FYI, Signal Group max at 10K users, and Keynote is aiming for group sizes of up to 50K.
@pfrazee.com I know you were saying this before, that the social private is hard and performance sensitive. I’m agreeing with you! And wondering if there are different ways to bucket this.
So, “yes, but” - I mention the doc editing not specifically as something that we need to try to handle in and of itself - but more to show that the behavior of swapping these kinds of permissions around has become a generalizable expectation of users. Offhand, I can’t think of any app I’ve regularly been exposed to that supports different levels of visibility/access with the expectation that you won’t be able to change it.
There’s the concept of “least surprise” in UX that I think we should at the very least acknowledge, and if there is an unexpected behavior, just be prepared for both the developer and user feedback.
And I’d absolutely agree that single author versus multi-author, or even synchronous vs async editing could definitely require different technical solutions - but at a generalizable mechanism that can sit on top (at the very least, as a UI), they may all fit into similar or the same buckets.
Out of curiosity though - does anyone have a use case where they wouldnt want the ability to swap between private/protected/public once its set?
I totally agree with you but the scale matters hence throwing bsky under the bus on this one for pulling this off!
Aligning UX is going to be THE thing that actually makes this “interoperable” and feel similar across apps.
OAuth scopes is the first piece of shared UX we have in ATProto.
we are nowhere close to having a consistent login experience or design elements (to be fair no one has worked on this)
A way to select groups that is consistent - eg a com.atproto.permission.list primitive maybe? - and as you’ve suggested, labeling, defining, and having an interface that makes it clear what is personal private, shared private, or public.
I appreciate Paul’s naming scheme to get us started!
(Unlisted might be one we also adopt for things that are public on the protocol but not available at an app layer)
When it comes to public / private switch, using the context from my permissioned spaces poc…
If you had a Bluesky like microblog, where user data was stored in a permissioned space and setup in such a way that it would work as today ( @verdverm.com on Bluesky ), then a user could move records between a public / private state by adjusting the permissions on that record.
I do believe the growing consensus is to not mix the concepts in the repo implementations and have clear delineations between the public and private/permissioned content (even though some of this content could be very “public”).
Private accounts are a bit harder, but also a spectrum.
Going from public → private is easy, going from private → public has nuance
For what it’s worth, the rubric is for scoring. It’s not a hard set of requirements; it’s just meant to help us know what properties we might be trading with a given solution. Any solution that hits 60% of those goals is pretty good, and 80% is excellent. So: if Bluesky can’t implement a “flip of a switch” private/public toggle, but a lot of other very good use-cases are handled, then that’s just life.